Task-conditioned adaptation of visual features in multi-task policy learning
CVPR 2024
Paper Code CVPR 2024 poster CVPR 2024 video

Abstract
Successfully addressing a wide variety of tasks is a core ability of autonomous agents, which requires flexibly adapting the underlying decision-making strategies and, as we argue in this work, also adapting the underlying perception modules. An analogical argument would be the human visual system, which uses top-down signals to focus attention determined by the current task. Similarly, in this work, we adapt pre-trained large vision models conditioned on specific downstream tasks in the context of multi-task policy learning. We introduce task-conditioned adapters that do not require finetuning any pre-trained weights, combined with a single policy trained with behavior cloning and capable of addressing multiple tasks. We condition the policy and visual adapters on task embeddings, which can be selected at inference if the task is known, or alternatively inferred from a set of example demonstrations. To this end, we propose a new optimization-based estimator. We evaluate the method on a wide variety of tasks of the CortexBench benchmark and show that, compared to existing work, it can be addressed with a single policy. In particular, we demonstrate that adapting visual features is a key design choice and that the method generalizes to unseen tasks given visual demonstrations.
Task-conditioned adaptation
Setup
All tasks considered in this work are sequential decision-making problems, where at each discrete timestep \(t\) an agent receives the last 3 visual frames (with height \(h\) and width \(w\)) as an observation \(\mathbf{v}_t \in \mathbb{R}^{3 \times h \times w \times 3}\) and a proprioception input \(\mathbf{p}_t \in \mathbb{R}^{d_a}\), and predicts a continuous action \(\mathbf{\hat{a}}_t \in \mathbb{R}^{d_a}\), where \(d_a\) is the dimension of the action space, which depends on the task at hand. We are provided with a training dataset of expert demonstrations to train a single policy, and for inference we study two different setups:
-
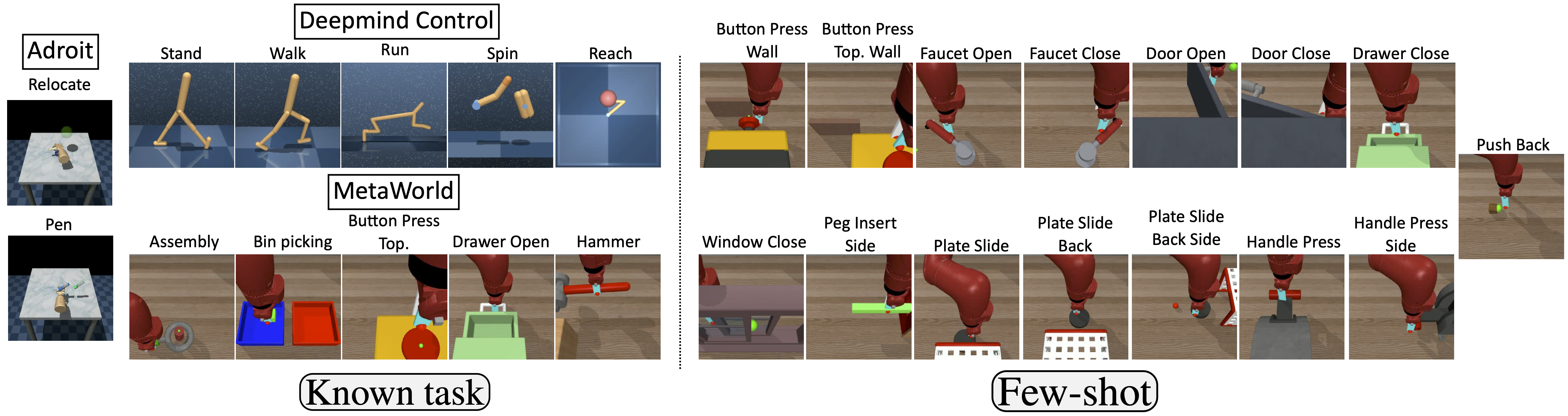
Known task: we a priori know the tasks to be executed. We consider here 12 robotics tasks from 3 benchmarks, i.e. Adroit, Deepmind control suite and MetaWorld.
-
Few-shot (unknown tasks): the trained policy must be adapted to a new unseen task without fine-tuning only given a small set of demonstrations. The ability of our method to adapt to new skills is evaluated on a set of 15 tasks from MetaWorld.
Base agent architecture
Following a large body of work in end-to-end training for robotics, the agent directly maps pixels to actions and decomposes into a visual encoder and a policy. The base visual encoder is a ViT model, which has been pre-trained with masked auto-encoding (MAE). More specifically, we keep pre-trained weights from VC-1.
Adaptation
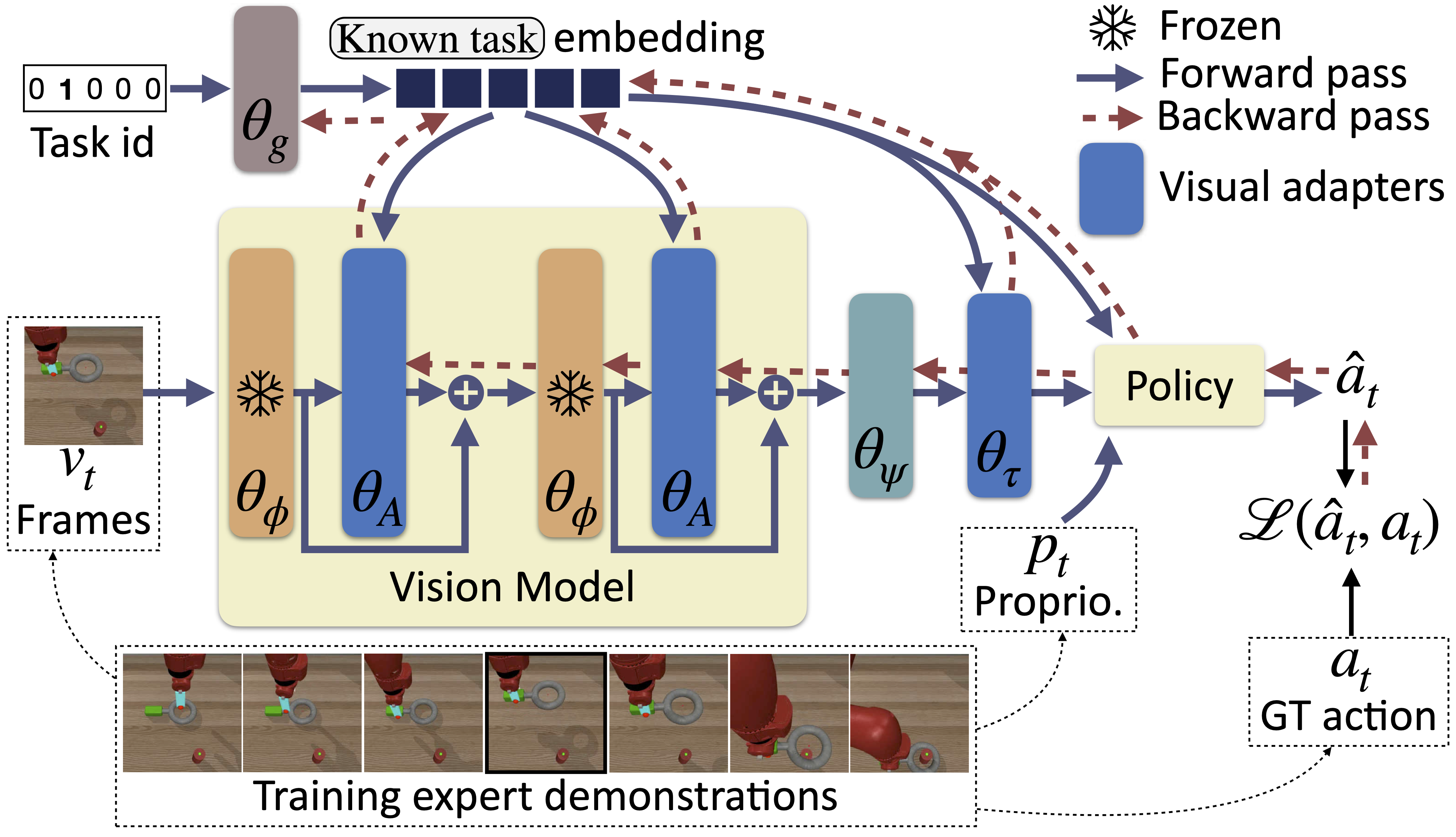
Our contributions are visual adapter modules along with a multi-task policy, which are all conditioned on the task at hand. This is done with a specific task embedding for each task, taken from an embedding space, which is aimed to have sufficient regularities to enable few-show generalization to unseen tasks. Importantly, the different adapters and the multi-task policy are conditioned on the same task embedding, leading to a common and shared embedding space.
Middle adapters
We add one trainable adapter after each ViT block to modulate its output. We introduce a set of middle adapters, where each adapter is a 2-layer MLP. In the modified visual encoder, each adapter modulates the output of the corresponding self-attention block and is conditioned on the task embedding. The output of a middle adapter is combined with the one of the self-attention layer through a residual connection.
Top adapter
A top adapter, also conditioned on the task at hand, is added after the ViT model, to transform the output to be fed to the multi-task policy (presented below). It has the same architecture as a single middle adapter.
Multi-task policy
We train a single MLP multi-task policy on the 12 considered known tasks. Its action space is the union of the action spaces of the different tasks. During training we apply a masking procedure on the output, considering only the actions possible for the task at hand.
Training
We train the model by keeping the weights of the pre-trained vision encoder (\(\theta_{\phi}\)) model frozen, only the weights of the adapter modules (\(\theta_A\) and \(\theta_{\tau}\) for middle and top adapters respectively), the multi-task policy, an introduced aggregation layer (\(\theta_{\psi}\) – see paper for more details) and the embedding layer (\(\theta_g\)) predicting the task embedding are trained. We train with imitation learning, more specifically Behavior Cloning (BC): for each known task, we have access to a set of expert trajectories that are composed of discrete steps, including expert actions.
Few-shot adaptation (task embedding search)
For the unknown setting, the task embedding is unknown at inference and needs to be estimated from a set of example demonstrations (sequences of demonstrations and actions). We exploit the conditioning property of the policy itself to estimate the embedding as the one which obtains the highest probability of the demonstration actions, when the policy is applied to the demonstration inputs.
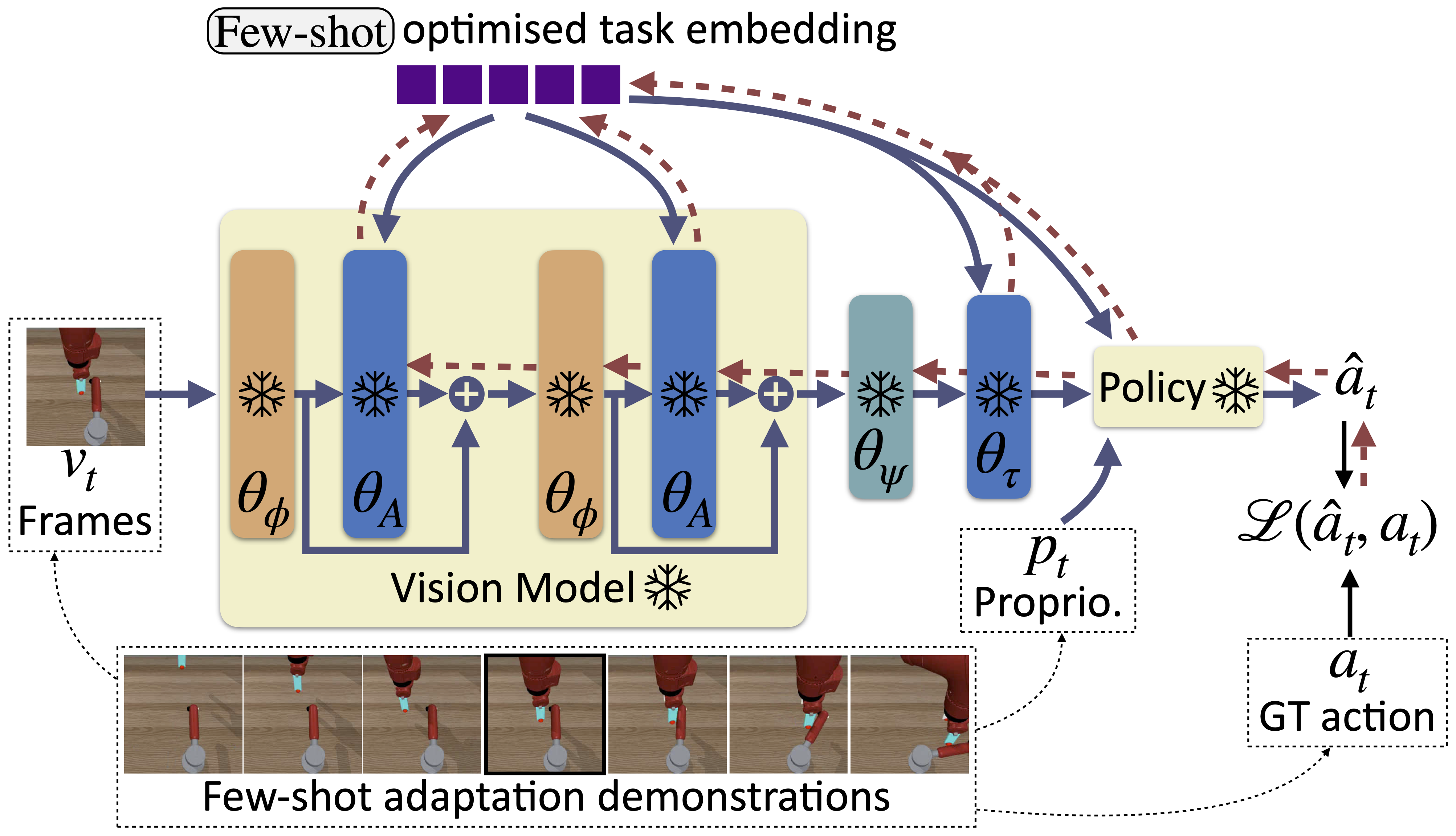
Inference
Policy inference is performed as follows, depending on whether we are addressing a known task or a new unknown task,

Quantitative results
All considered models are validated and then tested on two different held-out sets. Please see our paper for more details about our evaluation protocol.
Known tasks
Ablation study
We show below the mean test performance over the 12 known tasks of different variants of our model. Adding both middle (Middle ad.) and top (top ad.) adapters improves performance, as well as conditioning such adapters (C: conditioning / NC: no conditioning) on the task embedding.

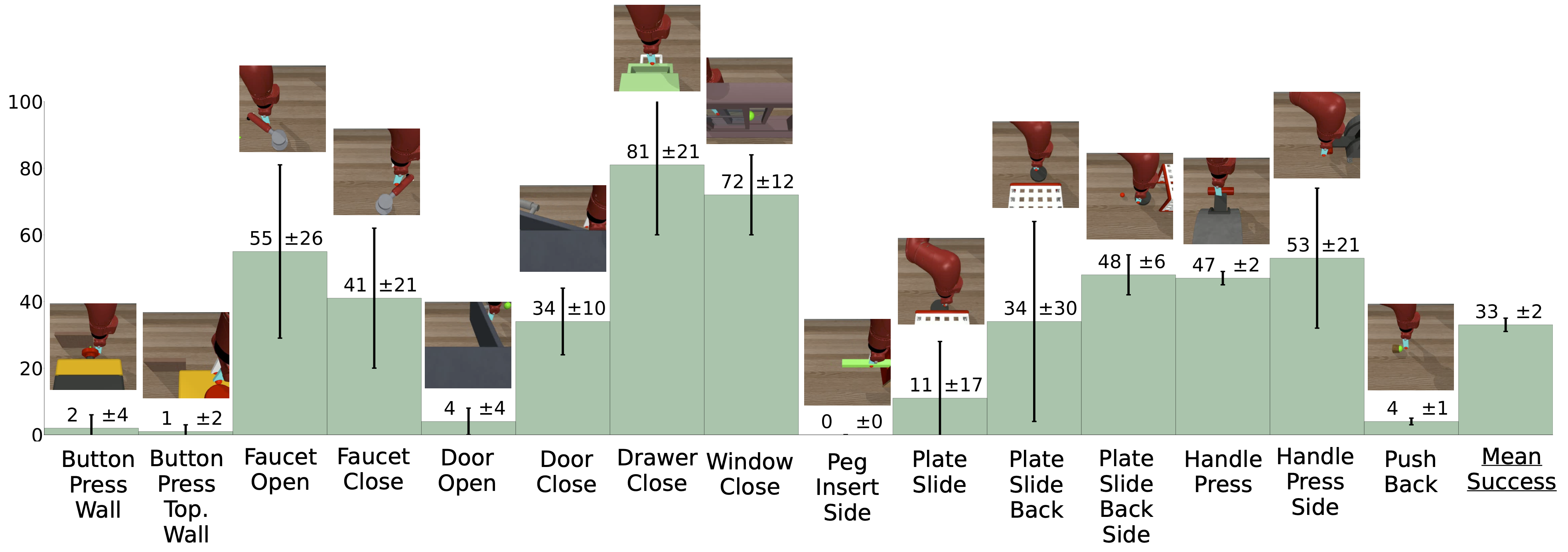
Per-task performance
We present the per-task test performance of the multi-task policy with and without adapters, along with single-task policies.

Few-shot (unknown tasks)
Here is the mean performance on new unknown tasks of our policy with task-conditioned adapters, after task embedding search with 5 demonstrations.