Teaching Agents how to Map: Spatial Reasoning for Multi-Object Navigation
IROS 2022

Abstract
In the context of visual navigation, the capacity to map a novel environment is necessary for an agent to exploit its observation history in the considered place and efficiently reach known goals. This ability can be associated with spatial reasoning, where an agent is able to perceive spatial relationships and regularities, and discover object characteristics. Recent work introduces learnable policies parametrized by deep neural networks and trained with Reinforcement Learning (RL). In classical RL setups, the capacity to map and reason spatially is learned end-to-end, from reward alone. In this setting, we introduce supplementary supervision in the form of auxiliary tasks designed to favor the emergence of spatial perception capabilities in agents trained for a goal-reaching downstream objective. We show that learning to estimate metrics quantifying the spatial relationships between an agent at a given location and a goal to reach has a high positive impact in Multi-Object Navigation settings. Our method significantly improves the performance of different baseline agents, that either build an explicit or implicit representation of the environment, even matching the performance of incomparable oracle agents taking ground-truth maps as input. A learning-based agent from the literature trained with the proposed auxiliary losses was the winning entry to the Multi-Object Navigation Challenge, part of the CVPR 2021 Embodied AI Workshop.
Multi-ON
We target the Multi-ON task, where an agent is required to reach a sequence of target objects, more precisely coloured cylinders, in a certain order, and which was used for a recent challenge organized in the context of the CVPR 2021 Embodied AI Workshop. Compared to much easier tasks like PointGoal or (Single) Object Navigation, Multi-ON requires more difficult reasoning capacities, in particular mapping the position of an object once it has been seen. The following capacities are necessary to ensure optimal performance: (i) mapping the object, i.e. storing it in a suitable latent memory representation; (ii) retrieving this location on request and using it for navigation and planning, including deciding when to retrieve this information, i.e. solving a correspondence problem between sub-goals and memory representation. The agent deals with sequences of objects that are randomly placed in the environment. At each time step, it only knows the class of the next target, which is updated when reached. The episode lasts until either the agent has found all objects in the correct order or the time limit is reached.
Baselines
We consider different baseline agents in this work. The differences between them are about the inductive biases given to the policy.
NoMap
NoMap is a recurrent baseline that takes as input at timetsetp \(t\) the previous action, target object class and RGB-D observation that is encoded using a CNN. This information is concatenated and fed to a GRU unit.
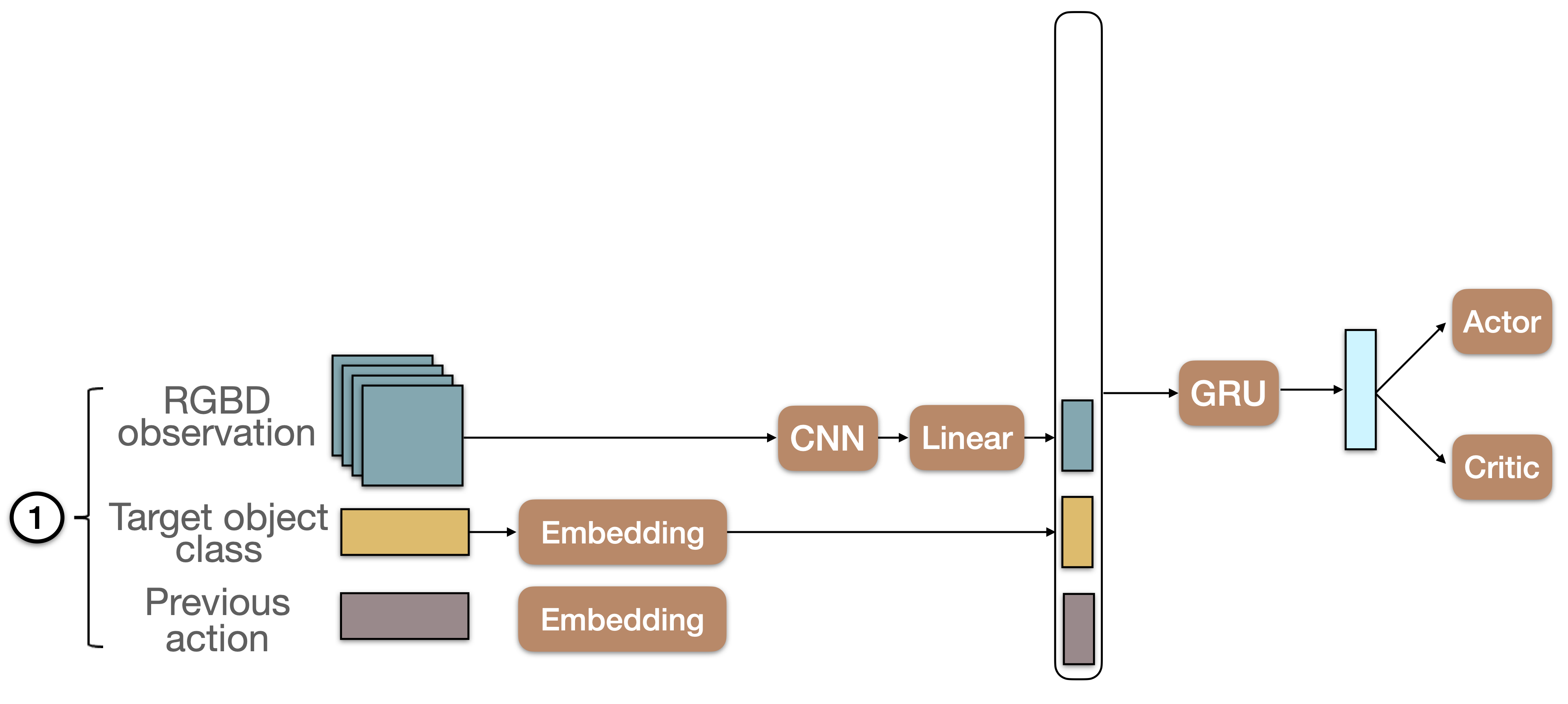
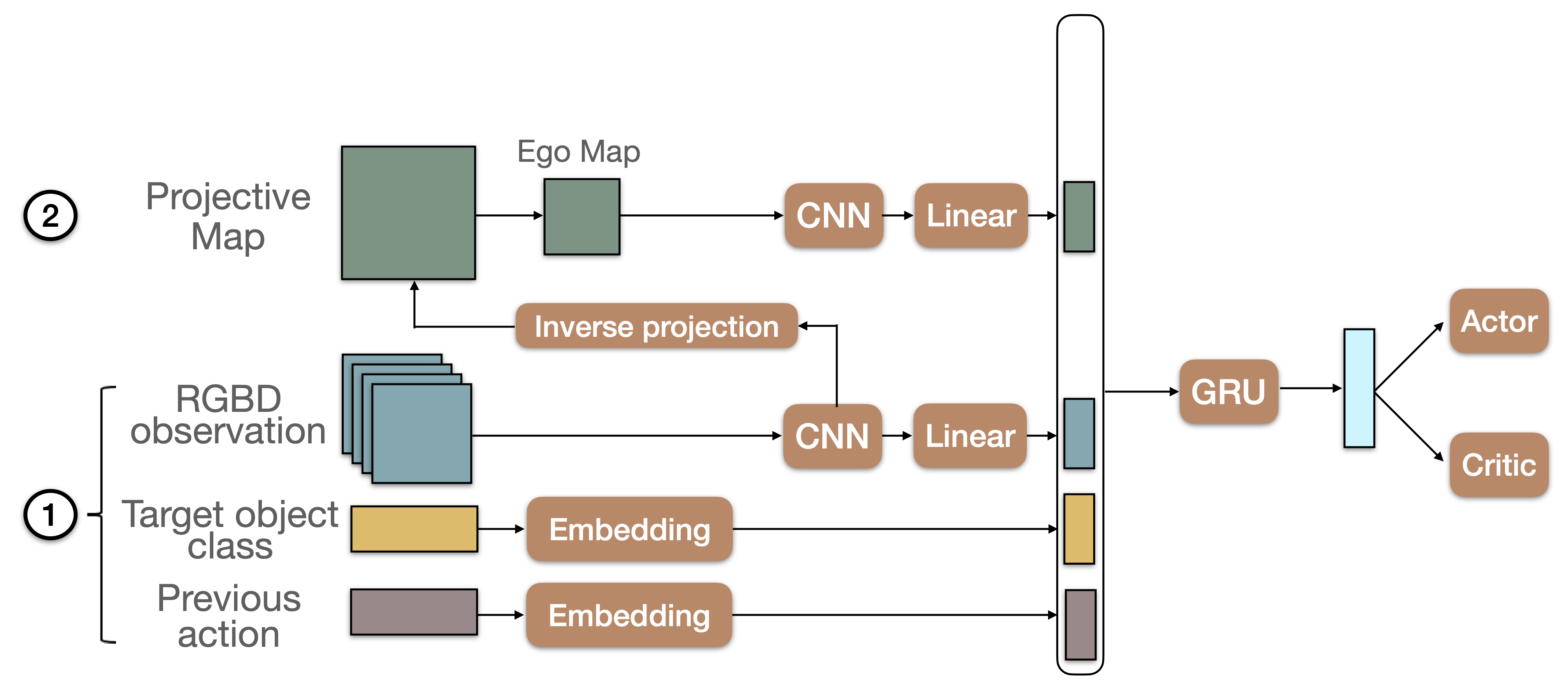
ProjNeuralMap
ProjNeuralMap builds a 2M map of the environment by projecting features from the CNN that takes the RGB-D observation as input. The projection is done using depth and camera intrinsics.
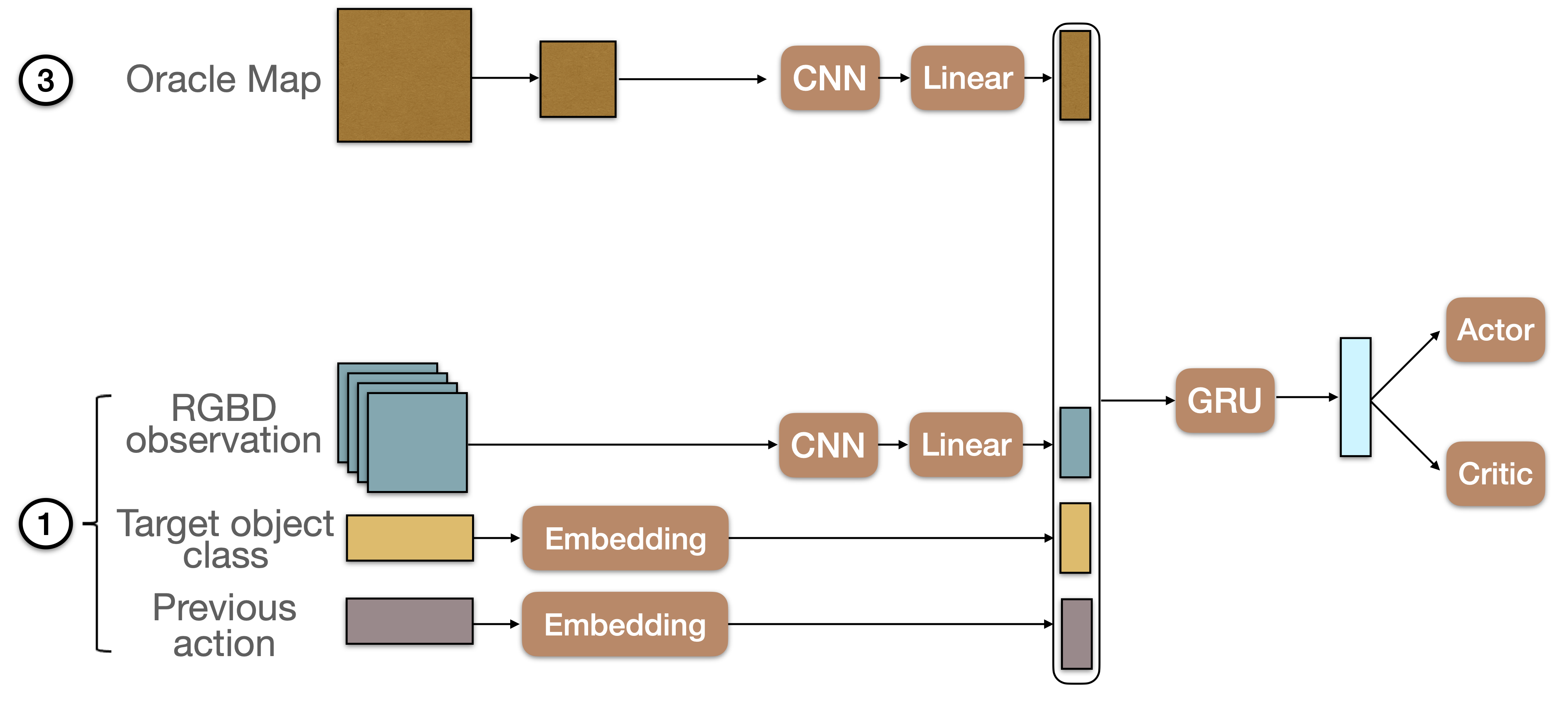
OracleMap
OracleMap is an oracle baseline that has access to priviledged information, namely a spatial grid map that spans the whole environment, and that contains occupancy information and target object locations.
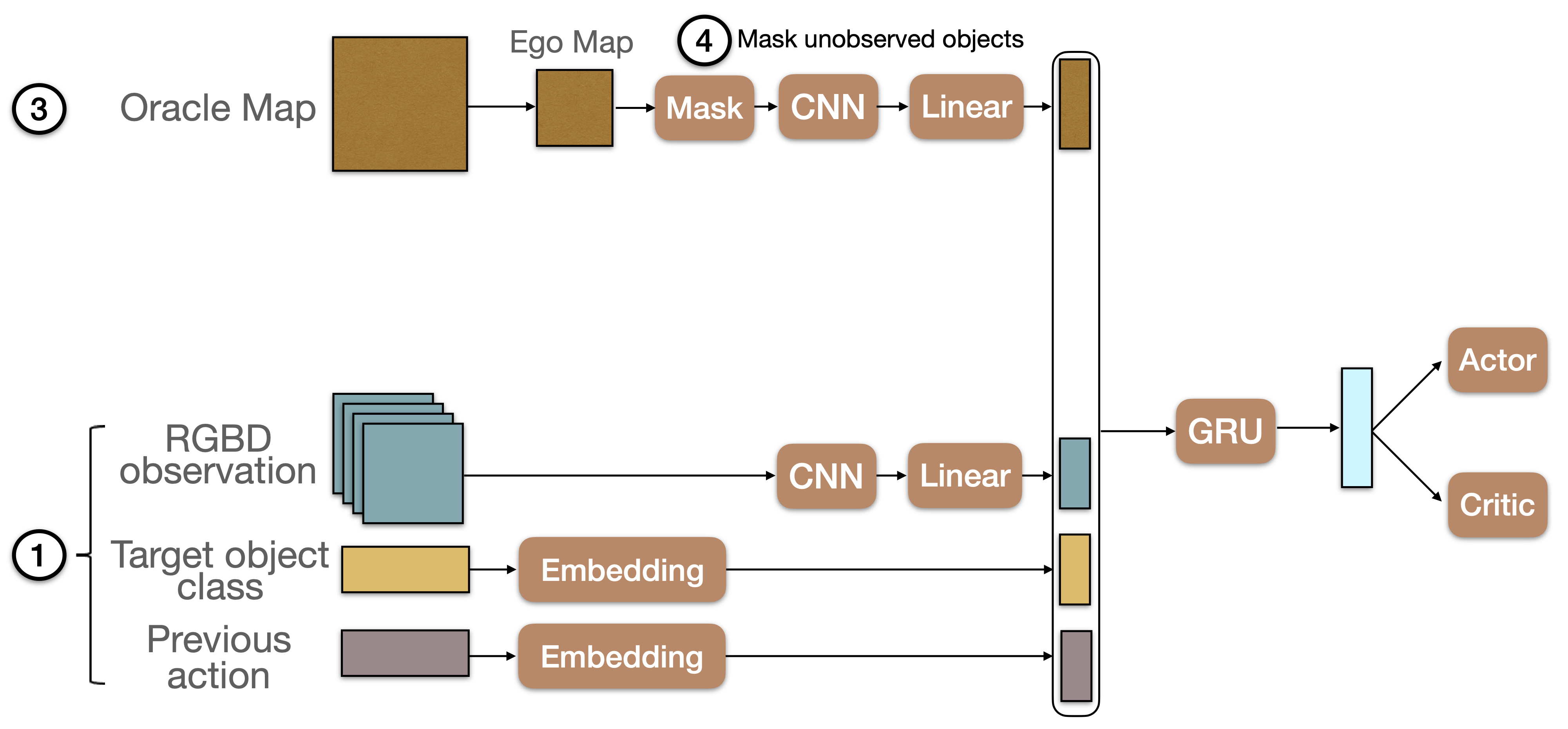
OracleEgoMap
OracleEgoMap is another oracle baseline that has access to location of target objects. A difference with OracleMap is that the map is only revealed in places that have already been within the agent’s field of view since the beginning of the episode.
Teaching Agents how to Map
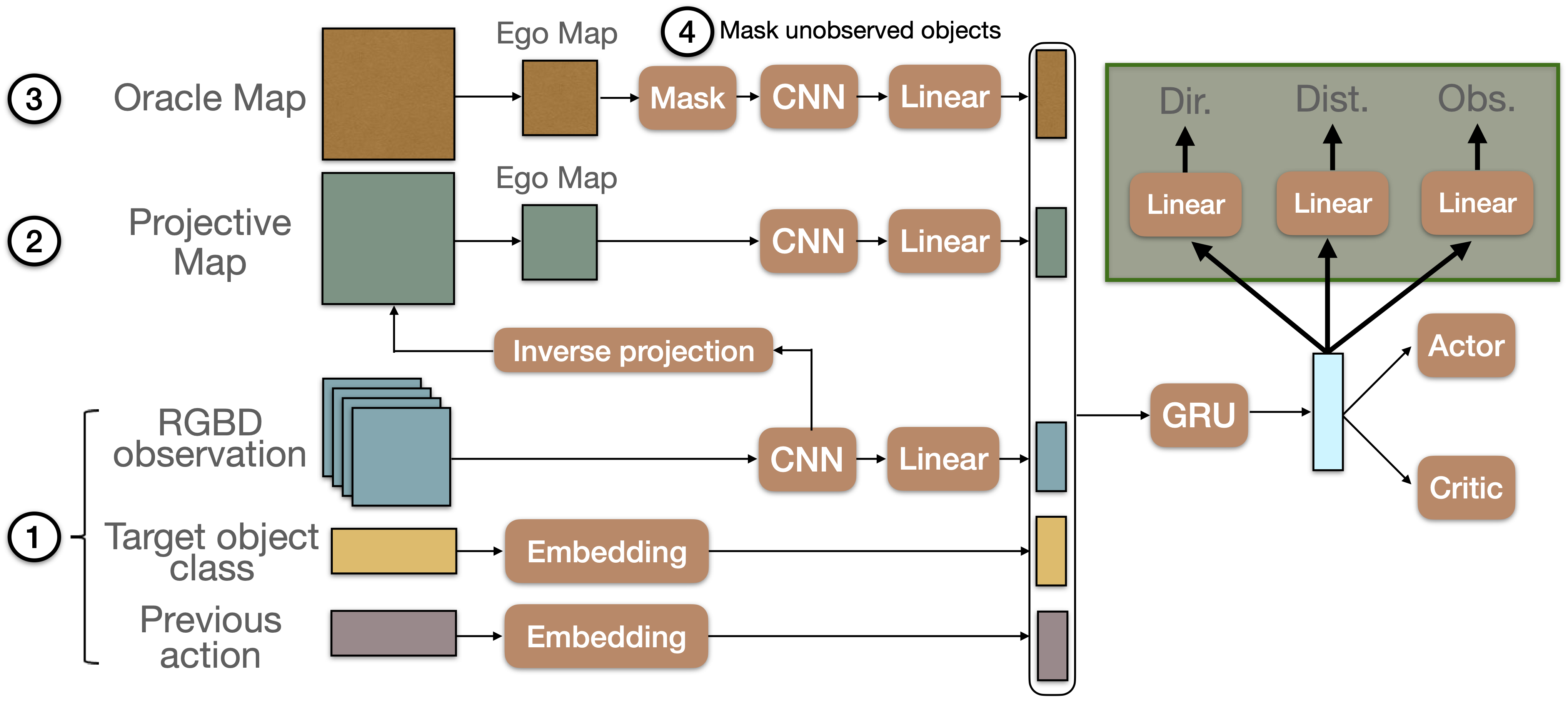
We introduce auxiliary tasks, additional to the classical RL objectives, and formulated as classification problems, which require the agent to predict information on object appearances, which were in its observation history in the current episode. To this end, the base model is augmented with three classification heads taking as input the contextual representation produced by the GRU unit. It is important to note that these additional classifiers are only used at training time to encourage the learning of spatial reasoning. At inference time, i.e. when deploying the agent on new episodes and/or environments, predictions about already seen targets, their relative direction are distance are not considered. Only the output of the actor is taken into account to select actions to execute.
-
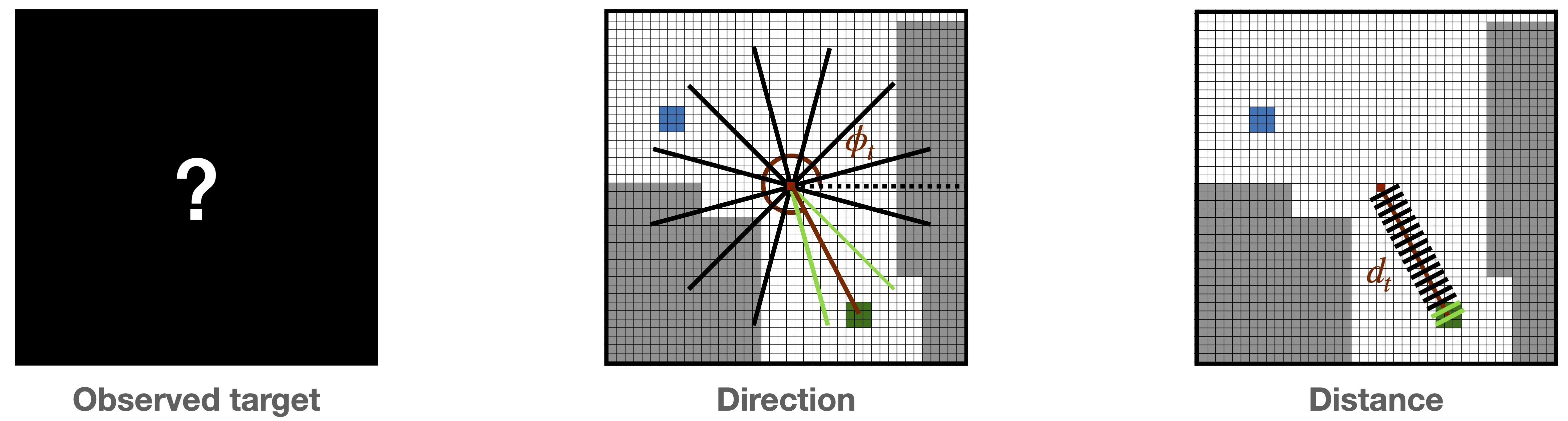
Direction: The agent predicts the relative direction of the target object, only if it has been within its field of view in the observation history of the episode.
-
Distance: The second task requires the prediction of the Euclidean distance in the egocentric map between the center box, i.e. position of the agent, and the mean of the grid boxes containing the target object that was observed during the episode.
-
Observed target: This third loss favors learning whether the agent has previously encountered the target object.
Results
We provide a summary of key results (only on the PPL metrics). Please read our paper for more details.
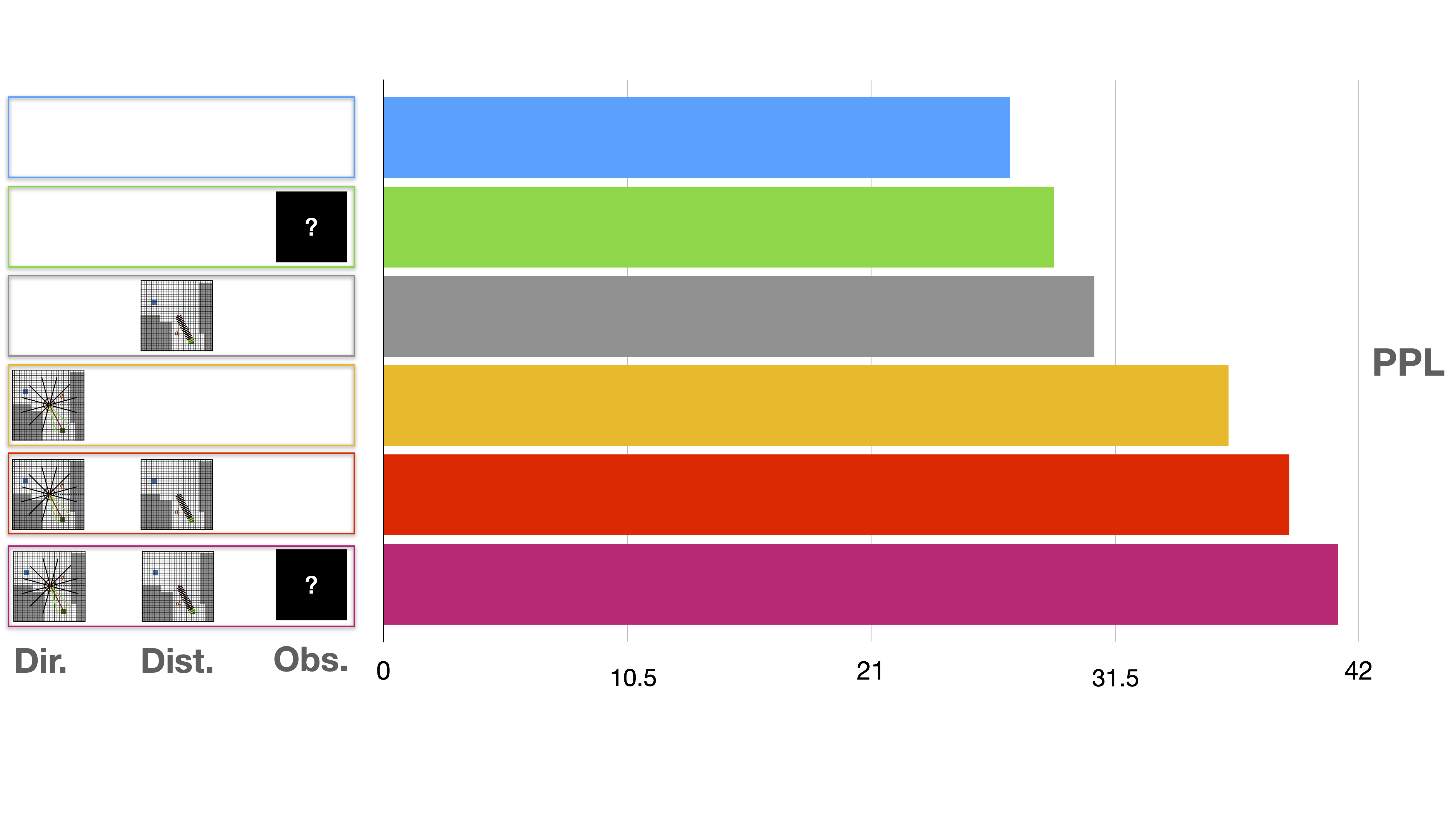
Ablation study
Augmenting the vanilla RL supervision signal with only one of the three auwiliary losses alone already brings a boost in performance. When combining direction and distance losses, PPL increases even more. Highest performance is achieved when combining the three axiliary tasks.
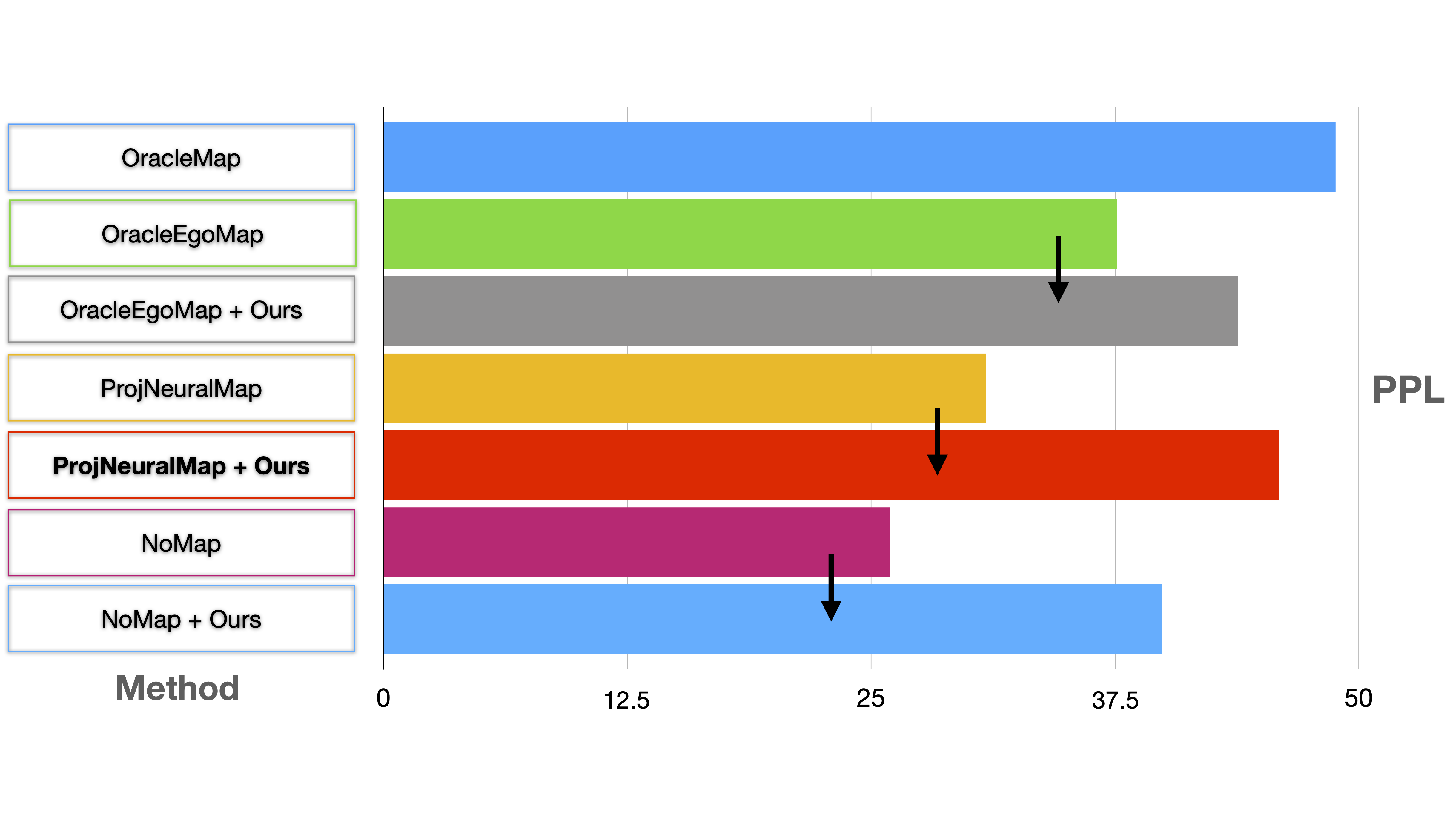
Comparison between baselines
The simple recurrent NoMap baseline performs surprisingly well when trained with our auxiliary losses, outperforming ProjNeuralMap trained with a vanilla RL objective. However, when augementing the training of ProjNeuralMap with the proposed auxiliary objectives, we reach state-of-the-art performance. Finally, even the OracleEgoMap baseline benefits from the additional supervision signal. As it already has access to some priviledged information, this might suggest the auxiliary losses help to learn to perform spatial reasoning.
Qualitative results
Below is a video prsenting a few evaluation episodes.
Multi-ON Challenge
The ProjNeuralMap baseline trained with our auxiliary losses was the winning entry to the CVPR 2021 Multi-ON Challenge part of the Embodied AI Workshop.