AutoNeRF: Training Implicit Scene Representations with Autonomous Agents
IROS 2024
Paper Code NeRF4ADR Workshop (ICCV 2023) poster
Abstract
Implicit representations such as Neural Radiance Fields (NeRF) have been shown to be very effective at novel view synthesis. However, these models typically require manual and careful human data collection for training. In this paper, we present AutoNeRF, a method to collect data required to train NeRFs using autonomous embodied agents. Our method allows an agent to explore an unseen environment efficiently and use the experience to build an implicit map representation autonomously. We compare the impact of different exploration strategies including handcrafted frontier-based exploration and modular approaches composed of trained high-level planners and classical low-level path followers. We train these models with different reward functions tailored to this problem and evaluate the quality of the learned representations on four different downstream tasks: classical viewpoint rendering, map reconstruction, planning, and pose refinement. Empirical results show that NeRFs can be trained on actively collected data using just a single episode of experience in an unseen environment, and can be used for several downstream robotic tasks, and that modular trained exploration models significantly outperform the classical baselines.

Reconstructing house-scale scenes
We start by illustrating the possibility of autonomously reconstructing complex large-scale environments such as apartments or houses from the continuous representations trained on data collected by agents exploring a scene using a modular policy. You can visualize RGB and semantics meshes (extracted from NeRF models) of 5 scenes from the Gibson val set. The semantics head of the NeRF models was trained with GT labels from the Habitat simulator.
Exploration Policy
The trained policy aims to allow an agent to explore a 3D scene to collect a sequence of 2D RGB and semantic frames and camera poses, that will be used to train the continuous scene representation. Following previous work, we adapt a modular policy composed of a Mapping process that builds a Semantic Map, a Global Policy that outputs a global waypoint from the semantic map as input, and finally, a Local Policy that navigates towards the global goal.
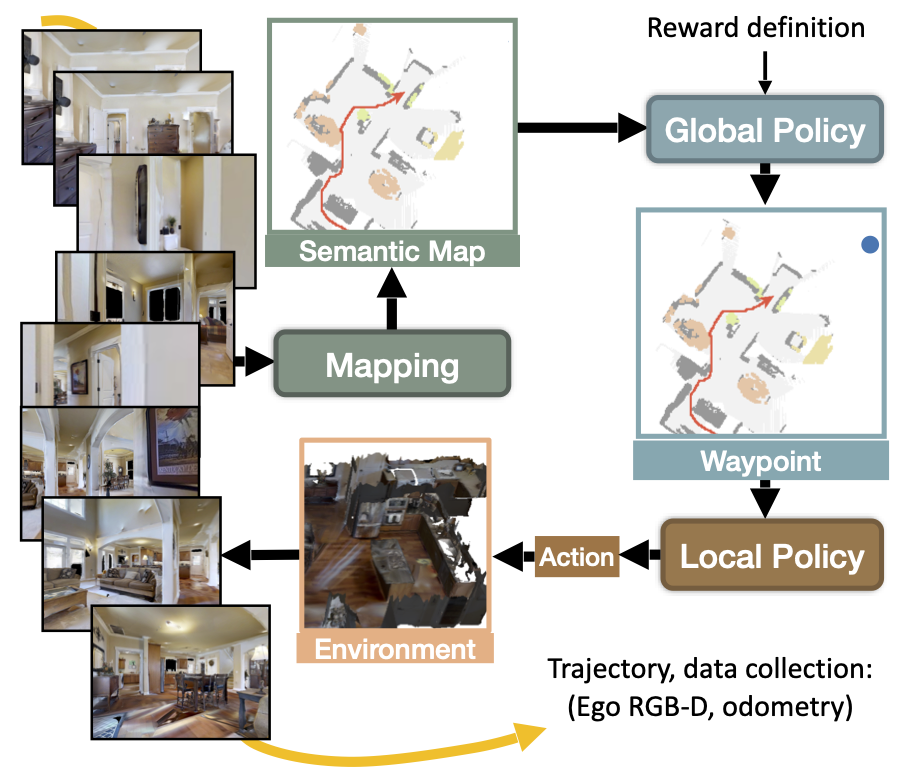
Reward definitions
We consider different reward signals for training the Global Policy tailored to our task of scene reconstruction, and which differ in the importance they give to different aspects of the scene. All these signals are computed in a self-supervised fashion using the metric map representations built by the exploration policy:
- Explored area — Ours (cov.) optimizes the coverage of the scene, i.e. the size of the explored area.
- Obstacle coverage — Ours (obs.) optimizes the coverage of obstacles in the scene. It targets tasks where obstacles are considered more important than navigable floor space, which is arguably the case when viewing is less important than navigating.
- Semantic object coverage — Ours (sem.) optimizes the coverage of the semantic classes detected and segmented in the semantic metric map. This reward removes obstacles that are not explicitly identified as a notable semantic class.
- Viewpoints coverage — Ours (view.) optimizes for the usage of the trained implicit representation as a dense and continuous representation of the scene usable to render arbitrary new viewpoints, either for later visualization as its own downstream task, or for training new agents in simulation. To this end, we propose to maximize coverage not only in terms of agent positions, but also in terms of agent viewpoints. Such reward functions does not only encourage to cover all objects in the scene, but also to view them from different viewpoints.
Downstream tasks
Prior work on implicit representations generally focused on two different settings: (i) evaluating the quality of a neural field based on its new view rendering abilities given a dataset of (carefully selected) training views, and (ii) evaluating the quality of a scene representation in robotics conditioned on given (constant) trajectories, evaluated as reconstruction accuracy. We cast this task in a more holistic way and more aligned with our scene understanding objective. We evaluate the impact of trajectory generation (through exploration policies) directly on the quality of the representation, which we evaluate in a goal-oriented way through multiple tasks related to robotics.
We present the different downstream tasks and qualitative results for Ours (obs.). A quantititative comparison between policies is presented in the paper.
Task 1: Rendering
This task is the closest to the evaluation methodology prevalent in the neural field literature. We evaluate the rendering of RGB frames and semantic segmentation. Unlike the common method of evaluating an implicit representation on a subset of frames within the trajectory, we evaluate it on a set of uniformly sampled camera poses within the scene, independently of the trajectory taken by the policy. This allows us to evaluate the representation of the complete scene and not just its interpolation ability.
Below are rendering examples, where the semantic head of the NeRF model was trained with GT semantic labels from the Habitat simulator. The same NeRF model will be used to provide qualitative examples in the next subsections.

Task 2: Metric Map Estimation
While rendering quality is linked to perception of the scene, it is not necessarily a good indicator of its structural content, which is crucial for robotic downstream tasks. We evaluate the quality of the estimated structure by translating the continuous representation into a format, which is very widely used in map-and-plan baselines for navigation, a binary top-down (bird’s-eye-view=BEV) map storing occupancy and semantic category information and compare it with the ground-truth from the simulator. We evaluate obstacle and semantic maps using accuracy, precision, and recall.
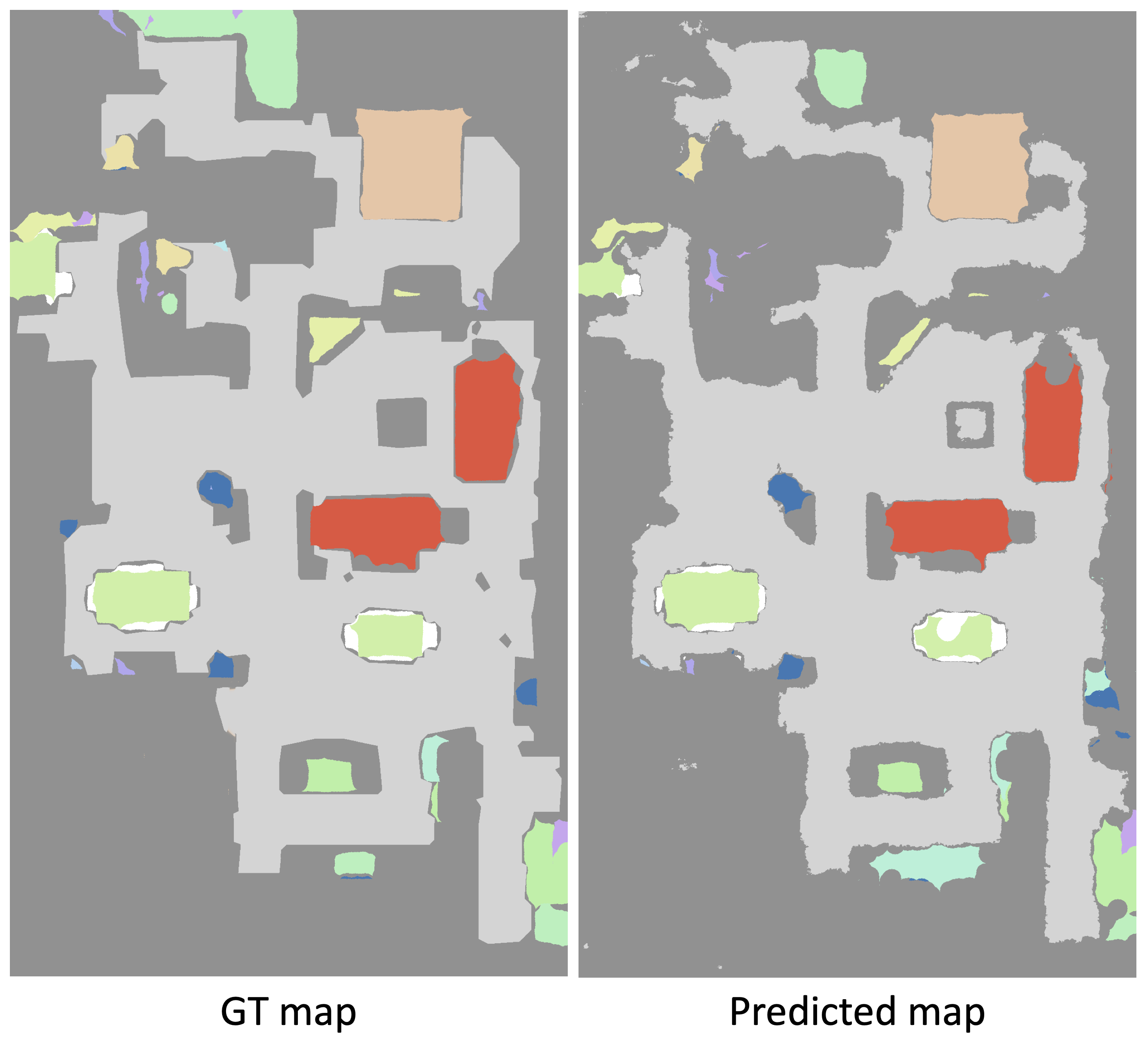
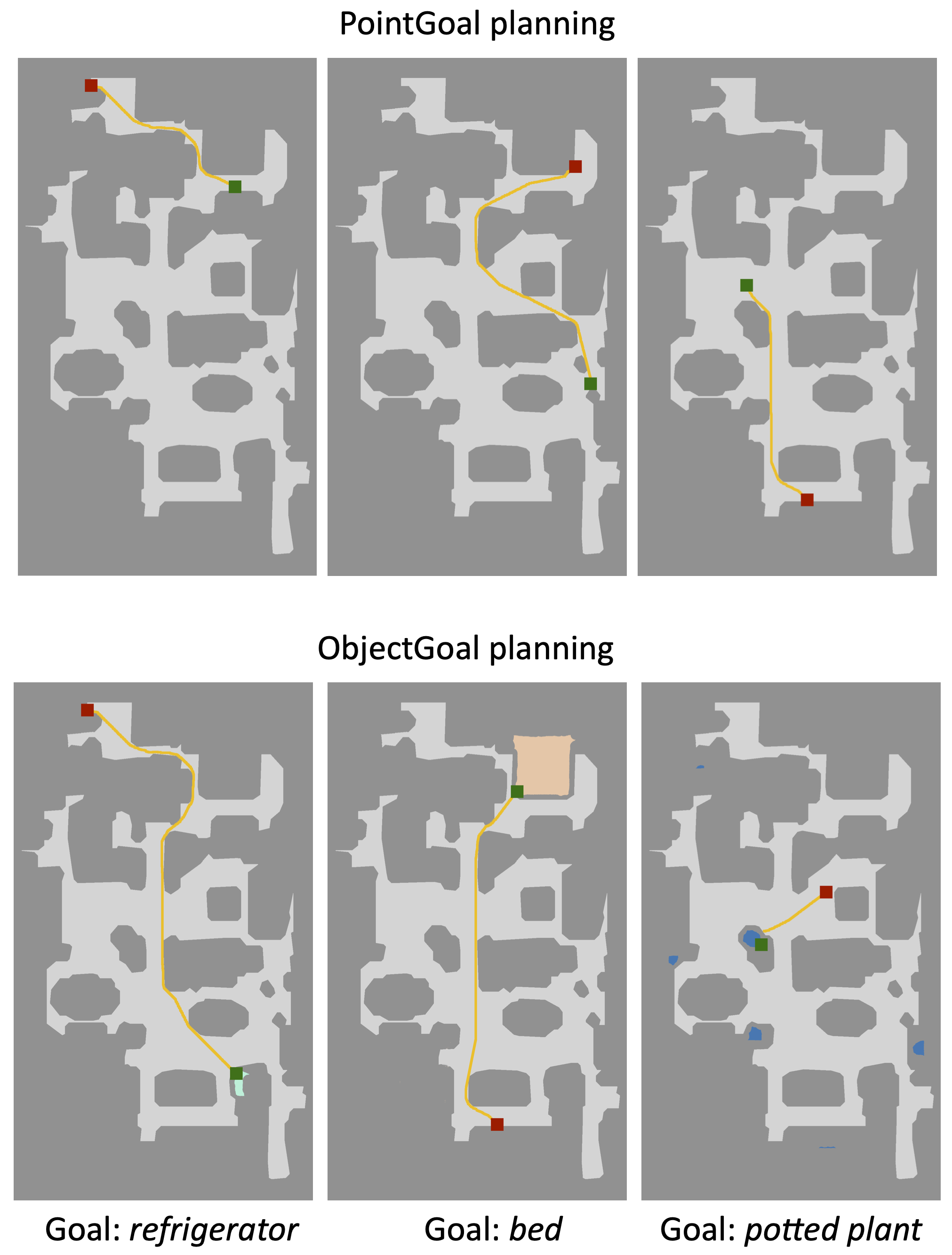
Task 3: Planning
Using maps for navigation, it is difficult to pinpoint the exact precision required for successful planning, as certain artifacts and noises might not have a strong impact on reconstruction metrics, but could lead to navigation problems, and vice-versa. We perform goal-oriented evaluation and measure to what extent path planning can be done on the obtained top-down maps.
Task 4: Pose Refinement
This task involves correcting an initial noisy camera position and associated rendered view and optimizing the position until a given ground-truth position is reached, which is given through its associated rendered view only. The optimization process therefore leads to a trajectory in camera pose space. This task is closely linked to visual servoing with a eye-in-hand configuration, a standard problem in robotics, in particular in its direct variant, where the optimization is directly performed over losses on the observed pixel space.
